
I love finding deals online and have been thinking a lot about how to monitor sites during this holiday season. The past few months I’ve been playing around with Google Chrome Puppeteer and thought it would be fun to use for a lab day to see what I could build around price monitoring. While doing some research and thinking a bit more about price monitoring, I had another interesting idea and direction, how cool would it be if you could detect a price based on a URL of a product.
After doing a bit of research, I realized some ecommerce sites are pushing pricing data using schema.org and in some cases, even their meta tags!

Examples: Meta Tags Example and Schema Example
This would make it very easy to pull out the price data as well as other useful data. I was going to start writing my own code, but found (someone already created one). After a bit more research, it turns out the company who built this plugin, indix, provides data on products and open sourced this component.
So I took their plugin and wrapped it with a Google Chrome Puppeteer script and now could pull down any URL.
Code for Script
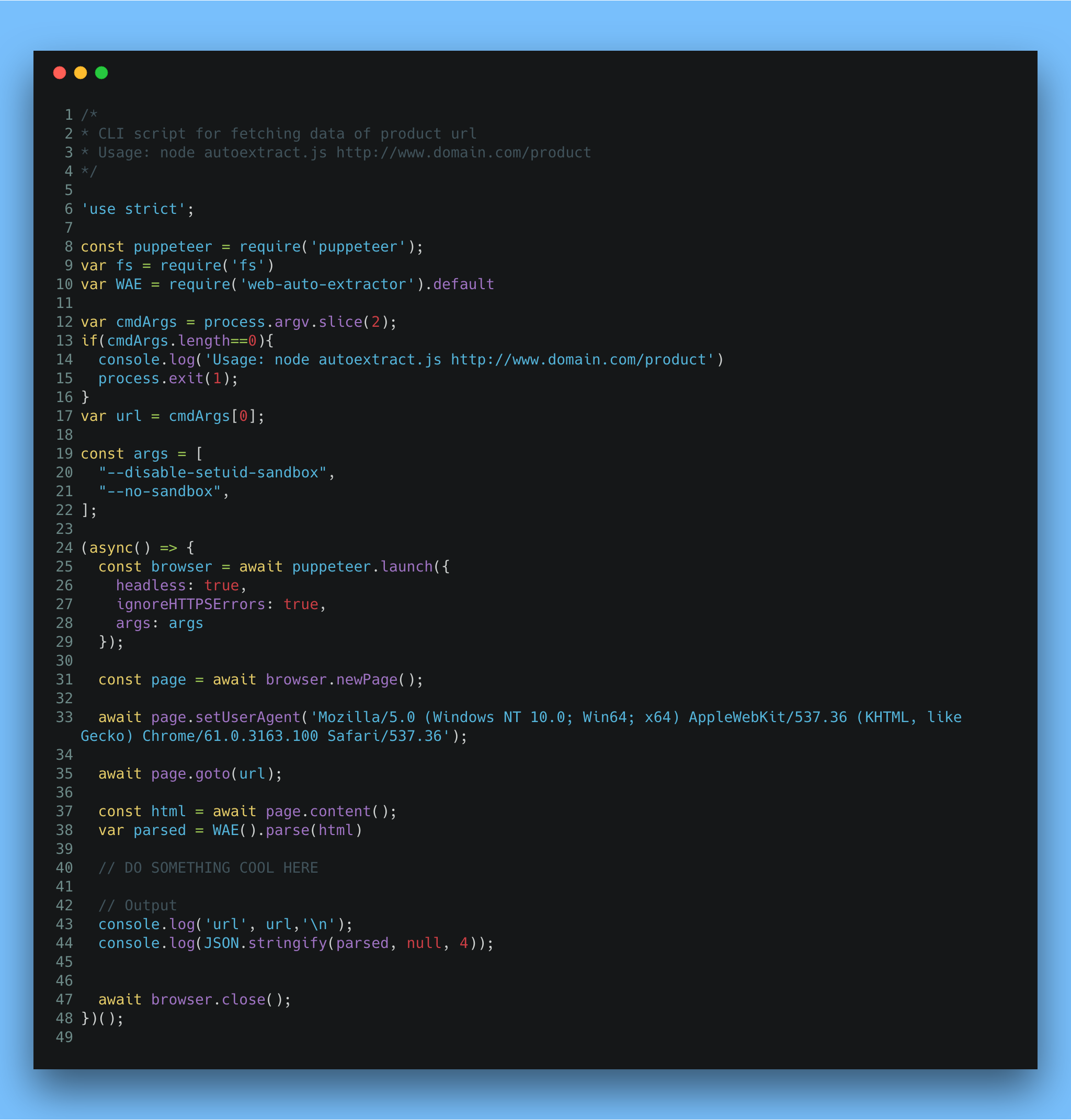
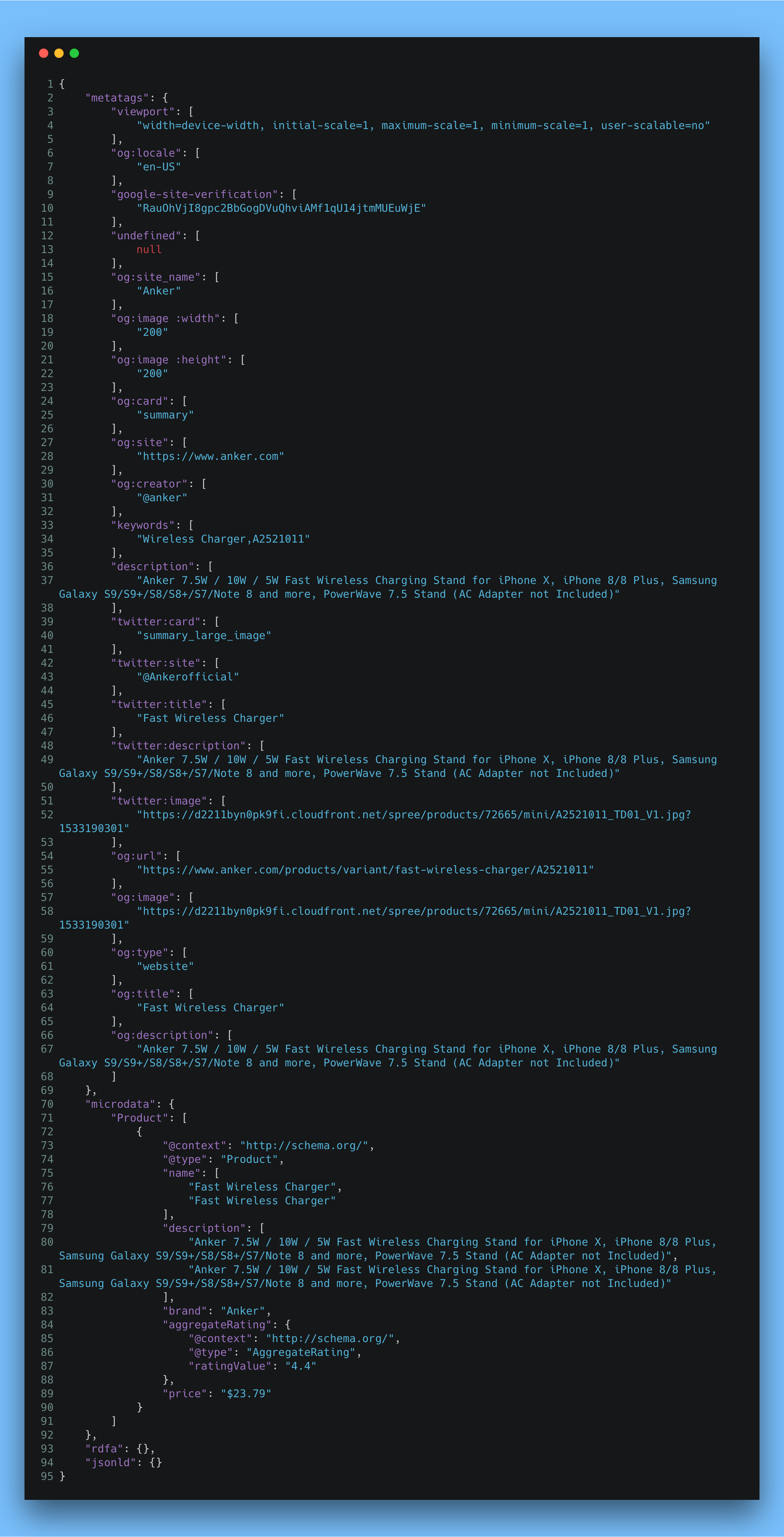
Example JSON of output from https://www.anker.com/products/variant/fast-wireless-charger/A2521011
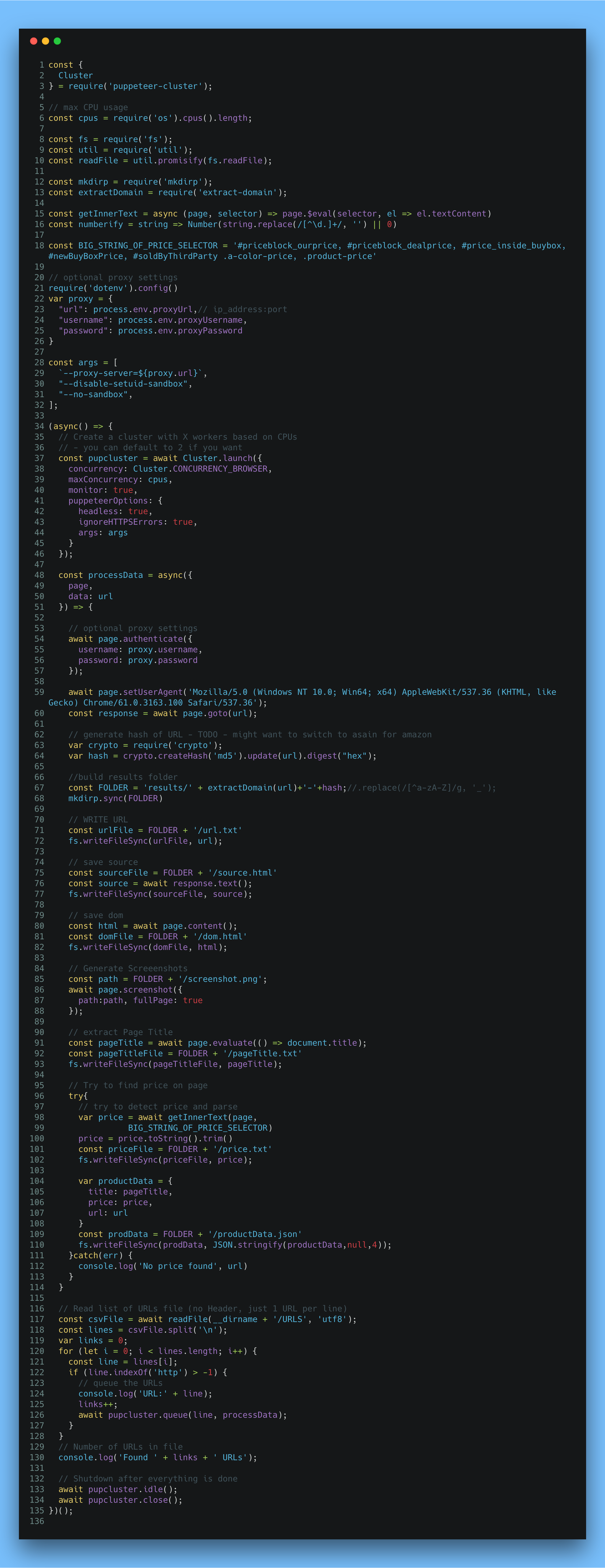
This is great to run as a one off test, but what if you have 100,000 URLs or more and want to get the data? I have used puppeteer-cluster in the past and knew I would want to build out more of a bot-like script that saves various forms of data and could run daily and/or check for changes (e.g. price monitoring).
This bot script reads in a file (1 URL per line, no headers) and then starts to process each URL on each thread. Although node is single threaded, you can run 1 thread per core and since my laptop has a few cores, I could run through a few URLs at the same time while grabbing another cup of coffee. I added a few things to this script for both saving the data in different formats (e.g. 1 json file vs one attribute like price as a single file). I had a few ideas around data storing and just wanted to keep my options open and stub out a few directions. I also took a crack at automating product price from Amazon pages, as I was shocked to find not all pages are coded the same. They use different ids for some of their pricing fields, you can end up with different prices for the same product.
So far these 2 scripts were working great and I wanted to combine them into more of a API/front-end website where a user could put in a URL or amazon ASIN and get back a variety of data from that page (e.g. price changes, high/lows, # of reviews, # of questions, etc.)
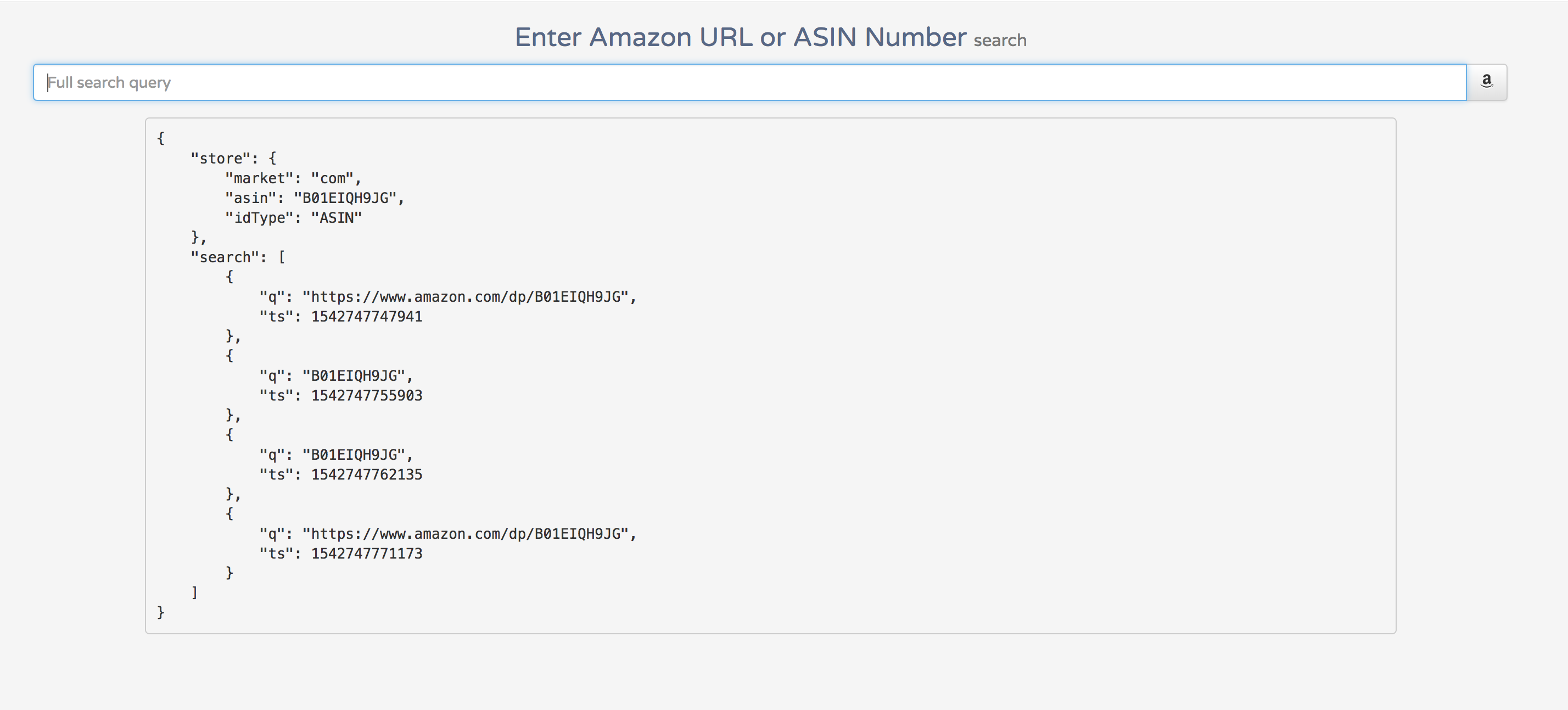
Although I ran out of time, I got to stub a few things together so you could put in an Amazon’s ASIN or URL and know that they are reference the same product. I also was looking at simple analytics for tracking the search (e.g. query and timestamp). Although I can run these scripts from my laptop, I would like to push it live and have it monitoring a few sites everyday without me needing to do anything. Maybe another lab day in the future.
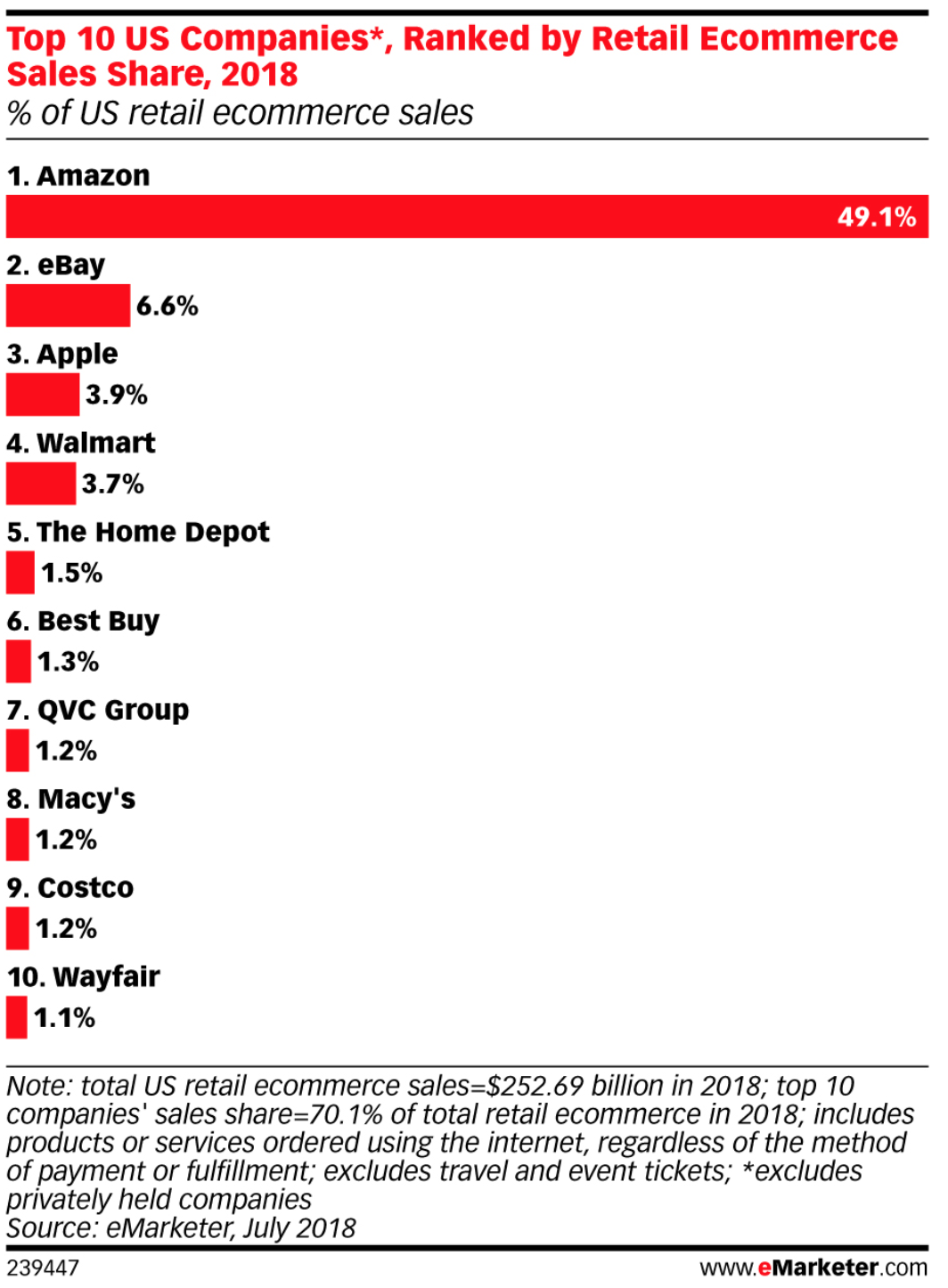
One more thing, I want to take a moment to showcase just how large Amazon is compared to all of online shopping. Checkout this chart!
I have posted the 2 scripts on github, so feel free to take them for a spin, pull requests welcome 🤓